現地時間9月12日、OpenAIはOpenAI o1を正式にリリースしました。新たにo1シリーズと名付けられたモデルには、OpenAI o1、OpenAI o1-preview、OpenAI o1-miniの3つのバージョンが含まれています。
現地時間9月12日、OpenAIはOpenAI o1を正式にリリースしました。新たにo1シリーズと名付けられたモデルには、OpenAI o1、OpenAI o1-preview、OpenAI o1-miniの3つのバージョンが含まれています。
現地時間9月12日、OpenAIはOpenAI o1を正式にリリースしました。新たにo1シリーズと名付けられたモデルには、OpenAI o1、OpenAI o1-preview、OpenAI o1-miniの3つのバージョンが含まれています。以前のモデルと比較して、これらのバージョンは、科学、プログラミング、数学における複雑なタスクをより適切に処理し、より困難な問題を解決することができます。
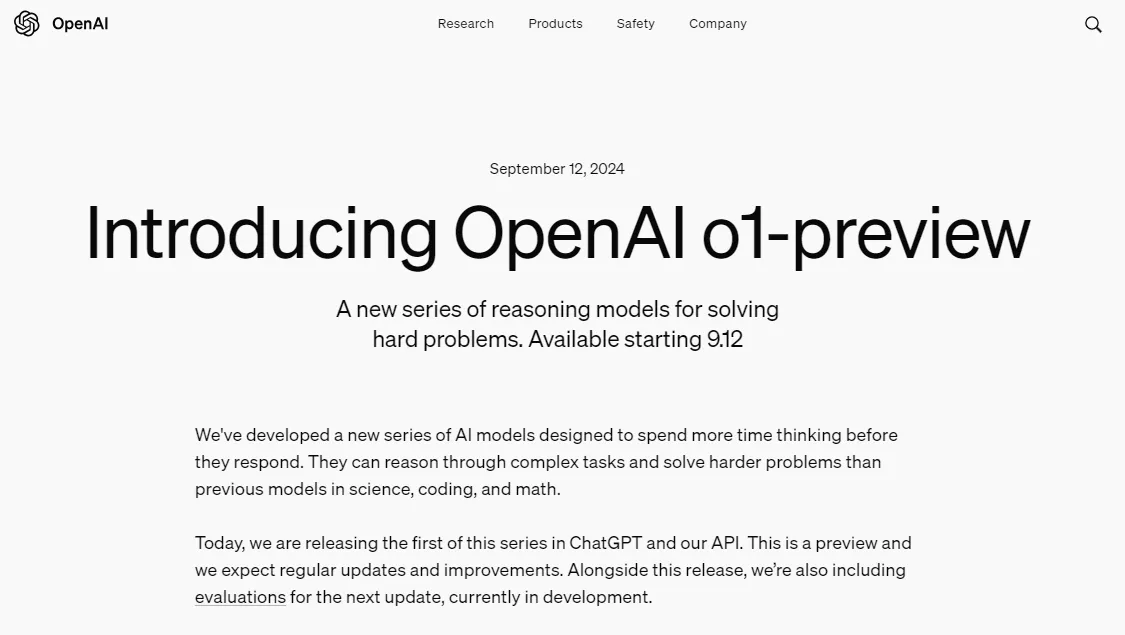
OpenAIのテストでは、新しいモデルは、物理学、化学、生物学の困難なベンチマークタスクで博士課程の学生に匹敵するレベルのパフォーマンスを示しました。数学とコーディングに優れており、国際数学オリンピック(IMO)予選で83%の正解率を達成し、プログラミングコンテスト(Codeforces)で89パーセンタイルに達し、博士レベルの科学問題テストで78%の正解率で人間の専門家を上回りました。
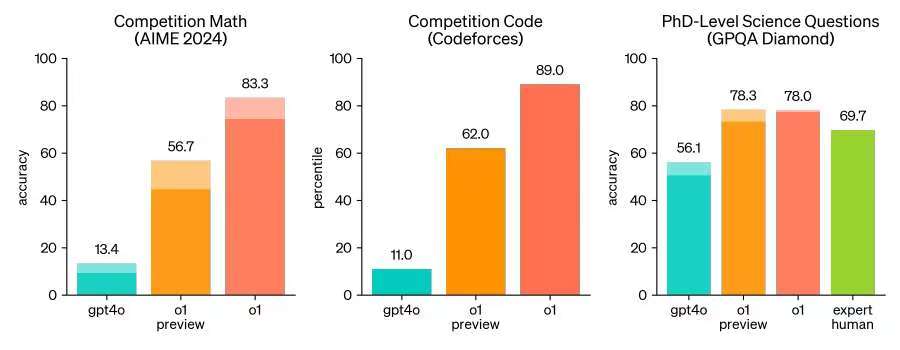
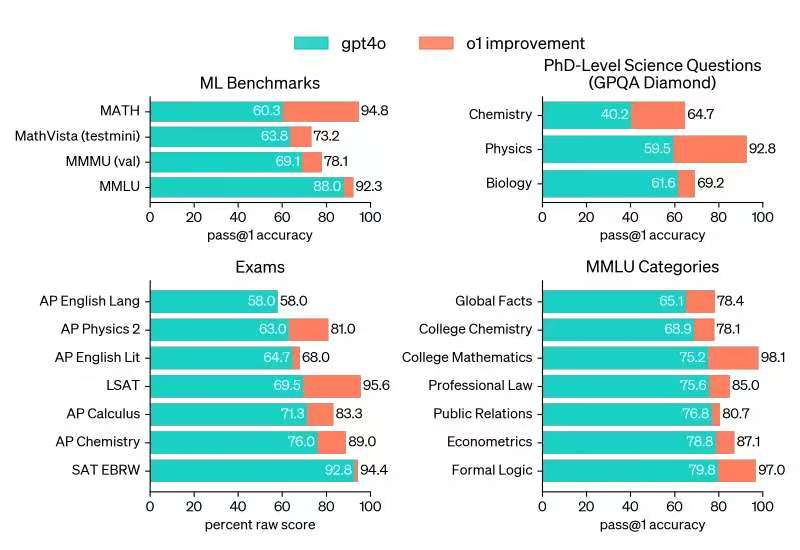
OpenAI o1は、複雑な推論を実行するために強化学習を通じてトレーニングされた新しい大規模言語モデル(LLM)です。以前は、大規模モデルは、主に厳密な論理とルールを欠く非構造化テキストデータに依存していたため、構造化された推論を実行できないと批判されることがよくありました。これにより、モデルは論理的な推論を実行したり、固定されたルールに従ったりするよりも、言語を生成することに長けていました。この問題に対処するために、OpenAIは思考の連鎖(CoT)メソッドを導入しました。OpenAI o1は、回答する前に考えます。ユーザーに応答する前に、長い内部の思考の連鎖を生成できます。o1モデルは、暗号、プログラミング、数学、クロスワード、英語、科学、安全性、健康などの分野で思考の連鎖を提示する能力をすでに実証しています。
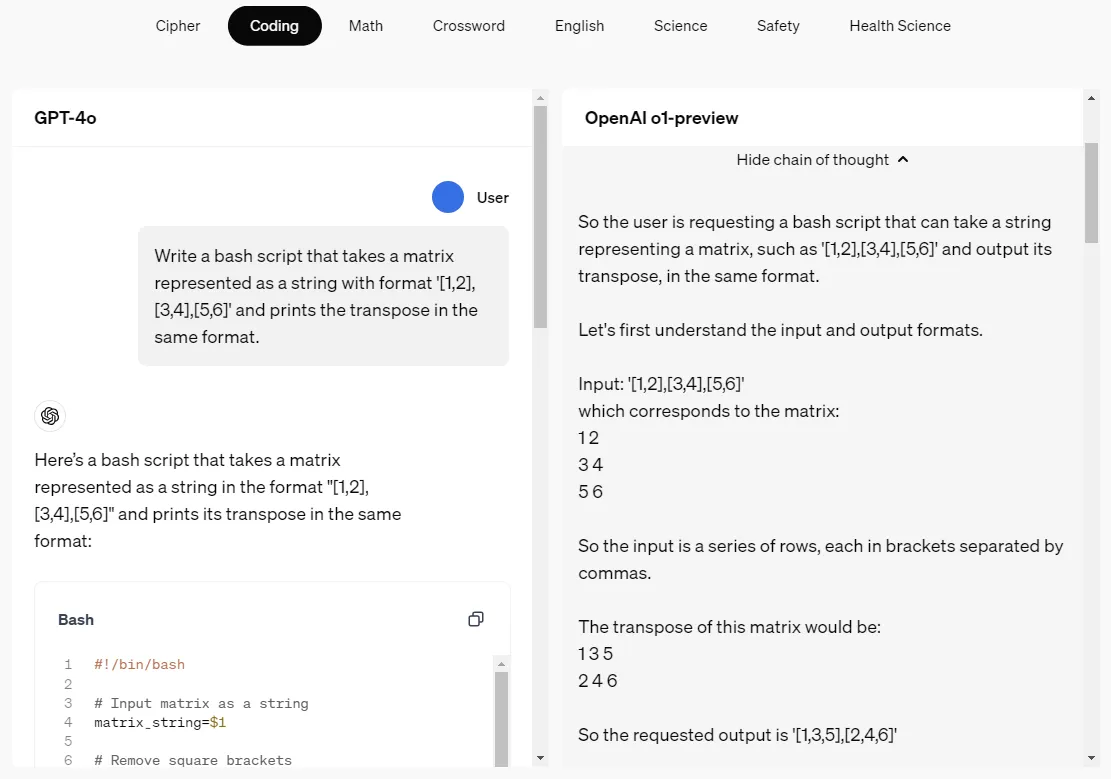
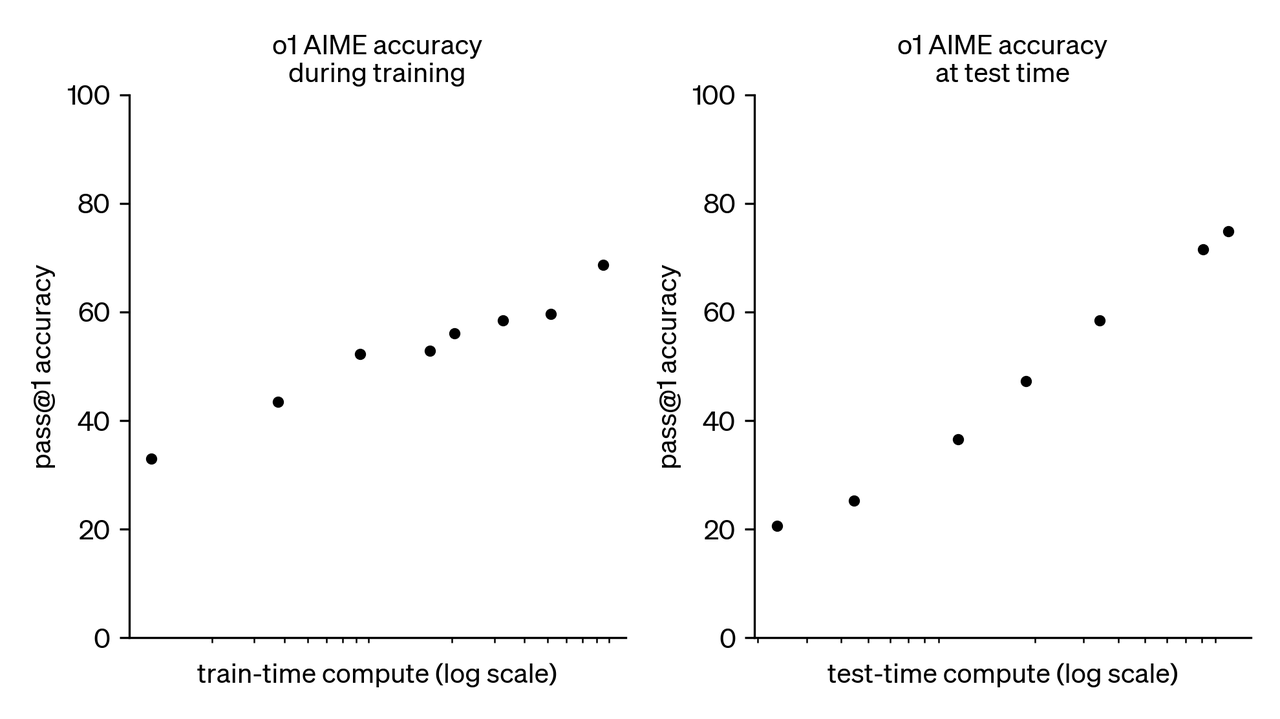
OpenAIの以前のモデルの思考モードはシステム1(直感的な経験に頼って迅速なフィードバックを行う)でしたが、o1モデルの思考の連鎖(CoT)はシステム2(論理的な推論に時間をかける)を活性化します。OpenAIは、大規模な強化学習アルゴリズムを使用して、o1モデルが非常に効率的なデータトレーニング中に思考の連鎖を効果的に利用する方法をトレーニングします。o1モデルは、人間のように、応答する前に問題について考える時間をより多く費やします。トレーニングを通じて、モデルは思考プロセスを洗練させ、さまざまな戦略を探求し、間違いを認識することを学びます。テスト結果は、o1モデルのアメリカ招待数学試験(AIME)の正解率が、強化学習(トレーニング時間)と思考時間(テスト時間)の向上に伴い継続的に増加することを示しています。OpenAIは、この方法のスケーリングの制限がLLMの事前トレーニングの制限とは大幅に異なることを発見し、これらの制約を引き続き研究します。この発見は、スケーリング則に新しい次元を追加し、モデルのパフォーマンスが強化学習トレーニングリソースの量と思考の連鎖の思考時間の2つの次元に沿って改善できることを示しています。
プログラミングシナリオを例にとると、OpenAI o1はプログラミングにさらなる可能性をもたらします。このモデルは、2024年の国際情報オリンピック(IOI)でスコア213で49パーセンタイルにランクインしました。各問題について、システムは多くの候補提出物をサンプリングし、テスト時間戦略に基づいてそのうちの50を選択します。提出物がランダムだった場合、平均スコアはわずか156になります。OpenAIは、提出制限が緩和されるとモデルのパフォーマンスが大幅に向上することを発見しました。問題ごとに10,000の提出が許可された場合、テスト時間選択戦略がなくても、モデルは362.14のスコアを達成し、金メダルのしきい値を超えました。OpenAIはまた、Codeforcesが主催する競争プログラミングコンテストをシミュレートして、モデルのコーディングスキルを実証しました。GPT-4oは人間の参加者の中で11パーセンタイルにランクインしましたが、o1モデルのEloレーティングは89パーセンタイルに大幅に向上し、微調整後、人間の競合相手の93%を上回りました。
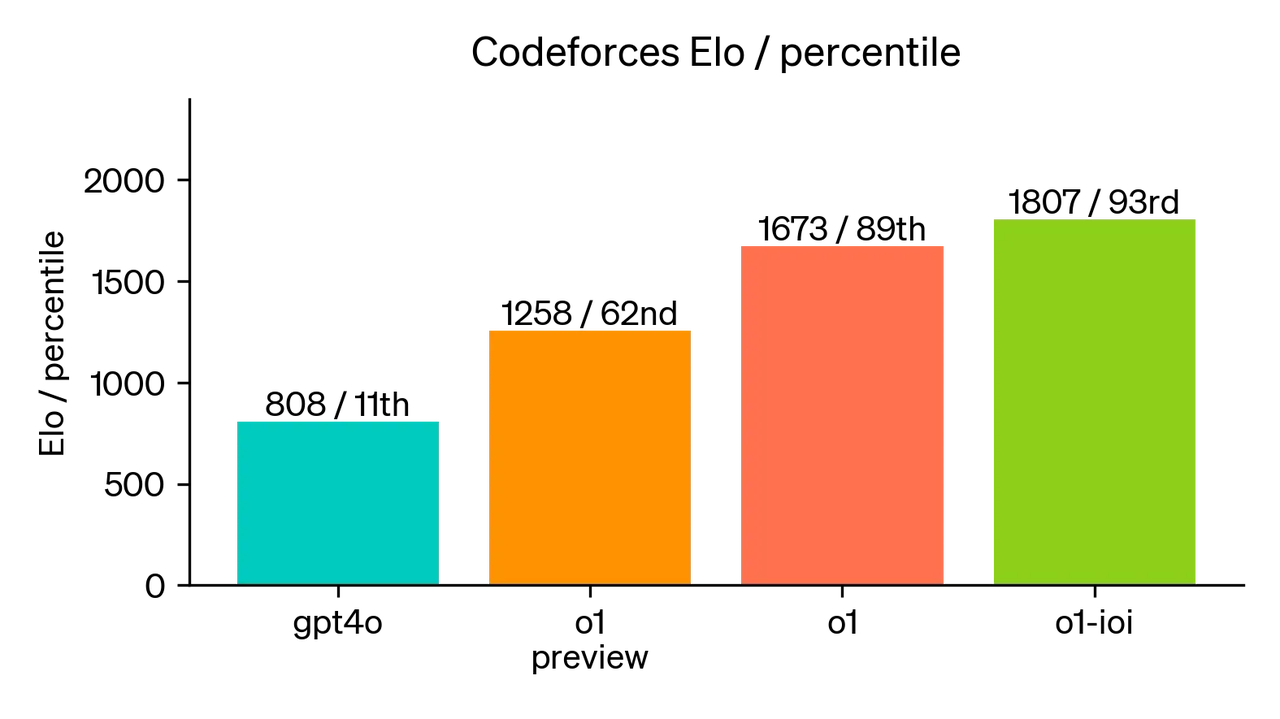
現在、OpenAI o1モデルはWebバージョンまたはAPI経由でアクセスできます。開発者にとって、OpenAI o1の使用は非常に高価です。比較すると、GPT-4oは入力100万トークンあたり5.00ドル、出力100万トークンあたり15.00ドルですが、GPT-4o miniは入力100万トークンあたり0.15ドル、出力100万トークンあたり0.60ドルです。さらに、o1モデルの思考の連鎖プロセスのトークン消費も出力トークンとしてカウントされるため、出力コストは大幅に高くなります。
OpenAI o1-previewは、広範な常識的知識を必要とする複雑なタスク向けに設計された新しい推論モデルです。128Kのコンテキストウィンドウと2023年10月までの知識を備えており、価格は次のとおりです。
入力:100万トークンあたり15.00ドル
出力:100万トークンあたり60.00ドル
OpenAI o1-miniは、プログラミング、数学、科学に特化した、高速で費用対効果の高い推論モデルです。また、128Kのコンテキストウィンドウと2023年10月までの知識を備えており、価格は次のとおりです。
入力:100万トークンあたり3.00ドル
出力:100万トークンあたり12.00ドル
OpenAI o1の強力な推論能力は、大規模モデルにおける新たな軍拡競争の始まりを告げています。o1モデルが科学、プログラミング、数学の複雑なタスクを処理する能力は、コーディング能力が大規模モデルの品質を評価する上で重要な要素になることを示唆しています。モデルの能力を向上させるには、データセットの量と質が大規模な強化学習アルゴリズムのトレーニングに大きな影響を与えるため、トレーニングの基盤として非常に効果的なデータセットが必要です。
前回の技術記事では、大規模モデルの数学的能力を高めることを目的とした一連のオープンソースの数学データセットを紹介しました。今回は、同様に重要なもう1つの分野、つまりモデルのコーディング能力に注目します。コードデータセットは、さまざまなプログラミング言語とパラダイムをカバーし、さまざまな難易度とタイプのタスクを含んで、モデルの論理的推論能力を包括的に評価および向上させる必要があります。
以下では、大規模モデルのコーディング能力をトレーニングおよび評価するために広く使用されているオープンソースのコードデータセットをいくつか紹介します。
HumanEvalデータセットは、コード生成モデルの能力を評価するためにOpenAIによって開発されたベンチマークテストセットです。このデータセットには、164のオリジナルのPythonプログラミング問題が含まれており、各問題には関数シグネチャ、docstring(関数の目的を説明)、実行可能なテストケース、および正規の参照実装が含まれています。
HumanEvalは、高品質で多様なプログラミングタスクを提供し、主にコード生成モデルの機能的な完全性と正確性を厳密に評価するために使用されます。HumanEvalは、「pass@k」メトリックを使用してモデルを評価します。これは、モデルによって生成されたk個の候補ソリューションのうち少なくとも1つがすべてのテストケースに合格する確率を測定します。この評価方法は、コードが単に合理的に見えるだけでなく、完全に機能的に正しい必要があることを考慮しているため、実際のプログラミングシナリオに近いものです。
https://github.com/github/CodeSearchNet
CodeSearchNetデータセットは、コード検索と理解能力を評価するために設計された大規模なベンチマークデータセットです。このデータセットには、GitHubから供給された数百万行のコードと関連する自然言語記述が含まれており、Python、JavaScript、Go、Java、PHP、Rubyなどの複数のプログラミング言語をカバーしています。
CodeSearchNetの決定的な特徴は、コードスニペットとそれに対応するdocstringまたはコメントで構成される、膨大な数のコードとドキュメントのペアを提供することです。
CodeSearchNetは、現在のコード検索および理解モデルの能力の診断をサポートし、関連する研究の進歩を促進します。CodeSearchNetを通じて、研究者はコード検索、コードと自然言語のマッチング、コード理解などのタスクにおけるモデルのパフォーマンスをテストおよび改善できます。特に、コードのセマンティクスと自然言語記述の関係を深く理解する必要があるシナリオでは、CodeSearchNetはモデルのパフォーマンスを評価および向上させるための効果的なベンチマークとして機能します。
https://github.com/microsoft/CodeXGLUE
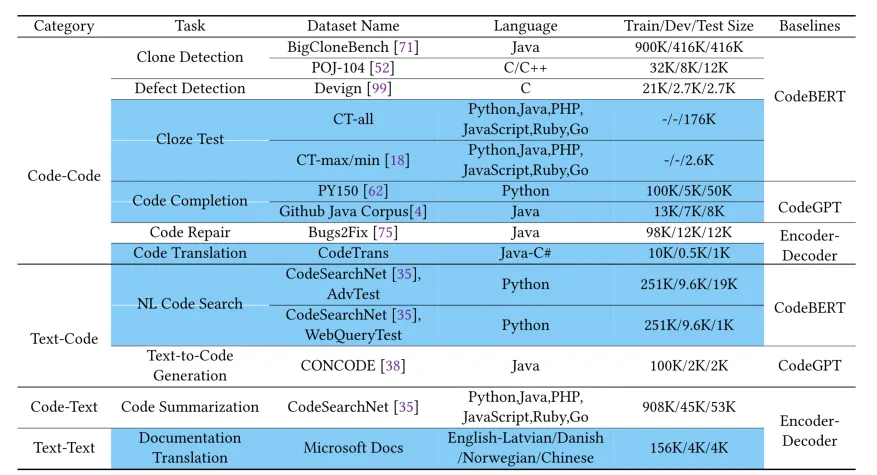
CodeXGLUEデータセットは、Microsoft Researchによって開発された包括的なコードインテリジェンスベンチマークです。このデータセットには、コードからコード、テキストからコード、コードからテキスト、コードから実行の4つの主要カテゴリをカバーする10の異なるコードインテリジェンスタスクが含まれています。各タスクには、特定のデータセット、評価メトリック、およびベースラインモデルの実装が付属しています。CodeXGLUEの決定的な特徴は、コードクローン検出からコード生成まで、さまざまな一般的なコードインテリジェンスアプリケーションを網羅する、多言語、マルチタスクの評価フレームワークを提供することです。
CodeXGLUEの独自性は、さまざまなモデル間のパフォーマンスを直接比較できる統一された評価フレームワークを提供することにあります。さらに、そのマルチタスク性により、研究者はモデルの汎化能力と転移学習能力を評価できます。
https://github.com/IBM/Project\_CodeNet
Project CodeNetは、コードインテリジェンス分野におけるAIの研究と応用を推進するためにIBM Researchによって開発された、大規模で多用途なデータセットです。55のプログラミング言語をカバーする1400万を超えるコードサンプルが含まれており、合計で約5億行のコードになります。
このデータセットは、各問題に対して複数の解決策と豊富なメタデータを含む、膨大な数の問題と解決策のペアを提供します。主な用途は次のとおりです。
コードの類似性分析
コード翻訳
コード補完と生成
プログラムの修復
計算量の推定
包括的なベンチマークとして、Project CodeNetは、特にコード構造、セマンティクス、および言語間の同等性を理解する上で、さまざまなコードインテリジェンスタスクにおけるモデルのパフォーマンスの評価と改善を可能にします。
https://huggingface.co/datasets/bigcode/the-stack-v2
The Stack v2は、BigCodeプロジェクトによって開発された大規模な多言語コードデータセットです。GitHubのオープンソースコードが含まれており、358を超えるプログラミング言語をカバーし、合計で約4.5TBのデータと2150億のトークンがあり、公開されている最大のコードデータセットの1つとなっています。
このデータセットは、主にコード分野における大規模言語モデルのトレーニングと研究をサポートするために使用されます。これには以下が含まれます。
専門的なコード理解および生成モデルのトレーニング
多言語コード表現と転移学習の研究
コード補完、検索、翻訳のためのツールの開発
コード構造とプログラミングパターンの調査
コード注釈とドキュメント生成の研究
The Stack v2の独自性は、一般的なプログラミング言語だけでなく、あまり一般的でない多くの言語も含む、データの多様性と規模にあります。これにより、言語間のコード理解研究に貴重なリソースが提供されます。複数のプログラミング言語を処理し、複雑なコード構造とセマンティクスを理解するモデルの能力を効果的に評価および改善します。
https://huggingface.co/datasets/google-research-datasets/mbpp
MBPPは、Google Researchによって開発されたPythonプログラミング問題セットで、974のオリジナル問題が含まれており、各問題には説明、解決コード、テストケースが付随しています。さまざまなプログラミングの概念とアルゴリズムをカバーする、基本的なものから中級レベルのPythonプログラミングタスクに焦点を当てています。
このデータセットは、主にコード生成モデルの評価、モデルのパフォーマンス向上、ベンチマークテストの提供、プログラミング教育のサポートに使用されます。モデルの自然言語理解、コード生成、構文の正しさ、機能の完全性、アルゴリズムの実装能力を効果的に評価します。MBPPの独自性は、文字列操作、リスト処理、数学計算など、実際のプログラミングで一般的なタスクタイプを網羅する、日常的なプログラミングの課題に焦点を当てている点にあります。
研究者はMBPPを使用して、専門的なPythonコード生成モデルをトレーニングし、Pythonタスクにおける大規模言語モデルのパフォーマンスを評価し、問題理解とコード生成の関係を研究し、インテリジェントなプログラミング支援ツールを開発できます。
https://github.com/THUDM/NaturalCodeBench
NaturalCodeBenchは、清華大学のTHUDMによって開発された包括的なコードインテリジェンスベンチマークです。複数の既存のコード評価データセットを統合し、新しい評価次元を導入して、コード能力を評価するためのより包括的で自然なフレームワークを提供することを目的としています。このデータセットは、主にコードモデル能力の包括的な評価、タスク間の比較、モデル改善の指導、および実世界のプログラミングシナリオのシミュレーションに使用されます。そのユニークな特徴には、多次元評価、コードの自然さの評価、データセット間の統合、難易度の階層化、多言語サポート、実際のプログラミングシナリオのシミュレーション、および継続的な更新をサポートする設計が含まれます。
NaturalCodeBenchにより、研究者はコードインテリジェンスモデルを包括的に評価および比較し、モデルの長所と短所を特定し、コード生成の自然さと実用性を向上させる方法を探求し、モデルの言語間およびタスク間の汎化能力を研究できます。
HumanEval-Xは、清華大学のTHUDMによって開発された多言語コード生成評価データセットであり、元のHumanEvalの拡張版として機能します。164のプログラミング問題が含まれており、各問題は6つの言語(Python、C++、Java、JavaScript、Go、およびRust)で実装されており、合計で984のタスクになります。
HumanEval-Xは、主にモデルの多言語コード生成能力、言語間転移学習能力、および言語に依存しないプログラミングスキルを評価するために使用されます。そのユニークな特徴には、複数の言語での並列実装、元の難易度レベルの維持、言語間の同等性の確保、および自動評価スクリプトの提供が含まれます。
https://github.com/hendrycks/apps
自動プログラミング進捗基準(APPS)は、UCバークレーの研究者によって開発された、コード生成モデルの能力を評価するための大規模なベンチマークです。このデータセットには、基本から上級までのさまざまな難易度レベルをカバーする10,000のオリジナルのプログラミング問題が含まれており、一部には競技レベルの課題も含まれています。
APPSの各問題には、詳細な問題の説明、関数シグネチャ、テストケース、および参照ソリューションが含まれています。この構造化されたデータ設計により、コード生成モデルを評価するための理想的なツールとなっています。APPSは主にPythonに焦点を当てていますが、他のプログラミング言語もサポートしており、柔軟性が向上しています。このデータセットには、生成されたコードの正しさを客観的にテストする自動評価スクリプトが装備されており、研究プロセスが大幅に簡素化されます。
APPSの主な応用は、コード生成モデルの総合的な能力、特に複雑で多様なプログラミングタスクを処理する際のパフォーマンスを評価することにあります。研究者はAPPSを使用して、問題の説明を理解し、正しい実装を生成するモデルの能力、およびさまざまな難易度レベルのタスクにおけるパフォーマンスをテストできます。
https://github.com/deepseek-ai/DeepSeek-Coder
DeepSeekは、前号で述べたように、数学分野で優れたパフォーマンスを発揮しただけでなく、コード分野でも驚くべき能力を示しています。今号では、DeepSeek-Coderの非オープンソースデータセットの生成プロセスを引き続き紹介します。

このデータセットは、主にコードデータと指示データの2つの部分で構成されています。コードデータは、公開されているコードリポジトリ、特にGitHubから供給され、重複コード、低品質コード、個人情報を含む可能性のあるコードの削除など、厳格なデータクリーニングとフィルタリングプロセスを経ています。指示データには、コード関連の質疑応答ペアと複数ターンの対話データが含まれており、一部は既存のオープンソースデータセットからキュレーションおよびフィルタリングされ、一部は大規模言語モデルを使用して合成データとして生成され、品質を確保するために手動でレビューされます。データ処理中、DeepSeek-AIはコードの解析とトークン化にtree-sitterを使用し、コードの構造情報を保持するために特定のエンコーディングスキームを適用し、重複排除と品質管理を実行します。
データがない
収集します。
データが煩雑
ラベリングします。
時間がない
既製品をご用意しています。
最も近いものをお選びください。あとはお任せください。
データがない
収集します。
データが煩雑
ラベリングします。
時間がない
既製品をご用意しています。
最も近いものをお選びください。あとはお任せください。